Documentation: HMC Toolbox for Data Mining
The HMC Toolbox for Data Mining is designed to harvest metadata of scientific literature publications, find data publications linked to these literature publication and to evaluate the latter with respect to specific aspects of the FAIR principles (cf. Wilkinson et al. (2016) (opens in a new tab)) using F-UJI as a first example of an automated assessment tool.
The various stages of the HMC Toolbox for Data Mining are summarized in the following figure:
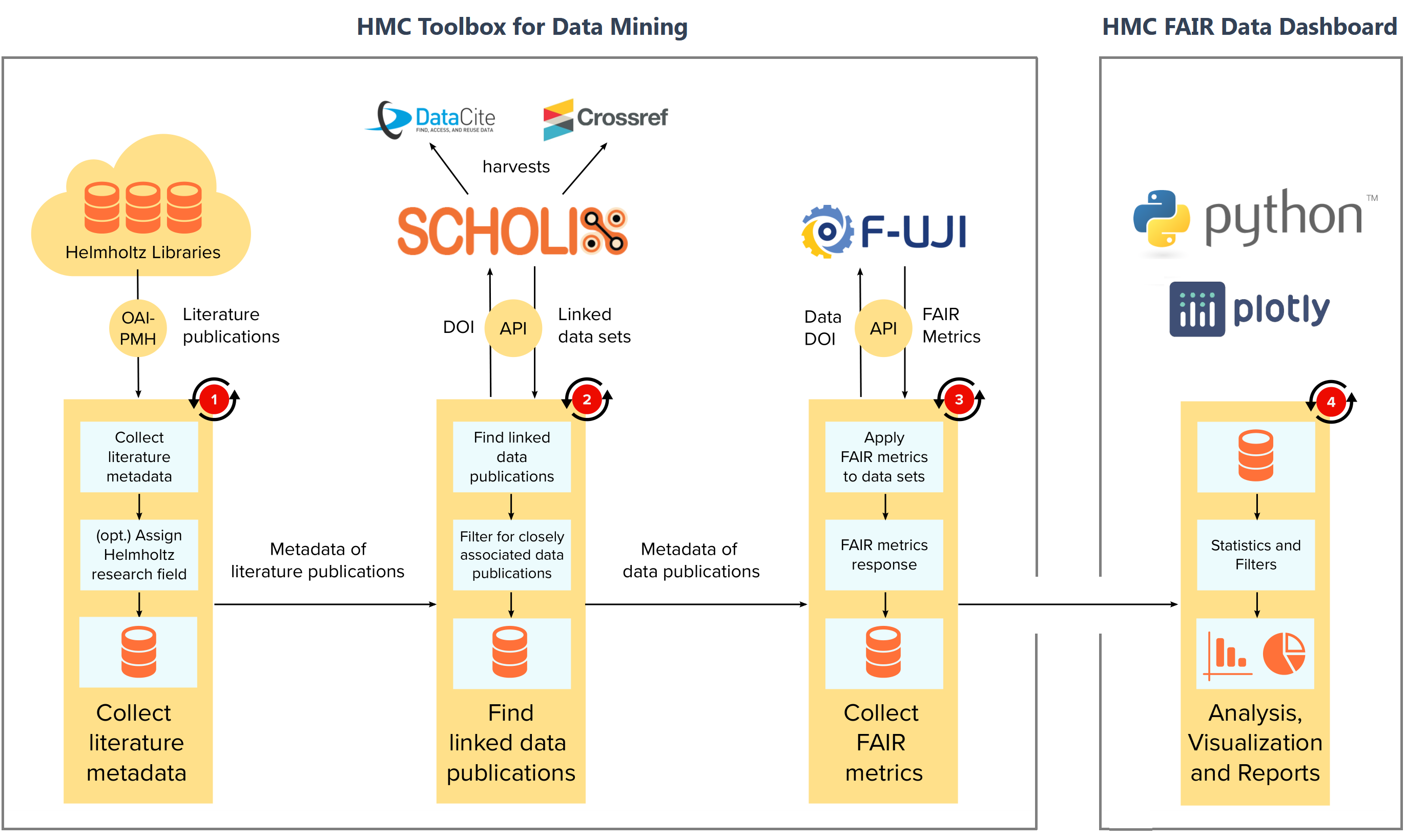
- Metadata of literature publications is harvested from the OAI-PMH (opens in a new tab)-endpoints provided by the libraries of the various Helmholtz centers.
- For each literature DOI found therein, linked data publications are harvested as Scholix links (cf. Burton et al. (2017) (opens in a new tab)) from the ScholeXplorer API (opens in a new tab). Linked data publications found with this approach are filtered for type
dataset, Scholix-relationship-typeIsSupplementedByand currently PID-typesdoiandhandle. - In the final step, each of the data publications identified is evaluated against specific aspects of the FAIR principles using the automated assessment tool F-UJI (cf. Devaraju, A. & Huber, R. (2020) (opens in a new tab)).
- The results are integrated into the HMC-instance of an interactive dashboard which is is accessible at https://fairdashboard.helmholtz-metadaten.de (opens in a new tab).
Structure of the project
The project is divided into two parts, represented by two project repositories and two sections in this documentation, respectively:
- The HMC Toolbox for Data Mining to harvest and automatically evaluate publication metadata. This part of the project is documented here under the currently opened tab Toolbox. All source code of this project part is available on GitLab (opens in a new tab) and Zenodo (opens in a new tab).
- HMC FAIR Data Dashboard to display interactive statistics of the metadata, previously harvested by the HMC Toolbox for Data Mining. This part is documented under the tab Dashboard at the top of this page. All source code of this part is available on GitLab (opens in a new tab) and Zenodo (opens in a new tab).
Disclaimer
Please note that the list of data publications obtained from data harvesting using the HMC Toolbox for Data Mining, as presented in the HMC FAIR Data Dashboard is affected by method-specific biases and is neither complete nor entirely free of falsely identified data. If you wish to reuse the data shown in this dashboard for sensitive topics such as funding mechanisms, we highly recommend a manual review of the data.
We also recommend careful interpretation of evaluation-results derived from automatized FAIR assessment. The FAIR principles are a set of high-level principles and applying them depends on the specific context such as discipline-specific aspects. There are various quantitative and qualitative methods to assess the FAIRness of data (see also FAIRassist.org (opens in a new tab) but no definitive methodology (see Wilkinson et al. (opens in a new tab)). For this reason, different FAIR assessment tools can provide different scores for the same dataset. We may include alternate, complementary methodologies in future versions of this project. To illustrate the potentials of identifying systematic gaps with automated evaluation approaches, in this dashboard you can observe evaluation results obtained from F-UJI (opens in a new tab) as one selected approach. Both, the F-UJI framework and the underlying metrics (opens in a new tab) are subject of continuous development. The evaluation results can be useful in providing guidance for improving the FAIRness of data and repository infrastructure, respectively, but focus on machine-actionable aspects and are limited with respect to human-understandable and discipline-specific aspects of metadata. Evaluations results obtained from F-UJI can be useful in providing guidance for improving the FAIRness of data and repository infrastructure, respectively, but cannot truly assess how FAIR research data really is.
How to cite this work
Scientific papers
- Kubin, M., Sedeqi, M.R., Schmidt, A., Gilein, A., Glodowski, T., Serve, V., Günther, G., Weisweiler, N.L., Preuß, G. and Mannix, O. (2024) "A Data-Driven Approach to Monitor and Improve Open and FAIR Research Data in a Federated Research Ecosystem", Data Science Journal, 23(1), p. 41. Available at: https://doi.org/10.5334/dsj-2024-041 (opens in a new tab).
Software publications
- Preuß, G., Schmidt, A., Gilein, A., Ehlers, P., Glodowski, T., Serve, V., Sedeqi, M. R., Mannix, O., & Kubin, M. (2024). HMC Toolbox for Data Mining (2.0.0). Zenodo. https://doi.org/10.5281/zenodo.14192982 (opens in a new tab)
- Sedeqi, M. R., Preuß, G., Gilein, A., Glodowski, T., Ehlers, P., Serve, V., Schmidt, A., Mannix, O., & Kubin, M. (2024). HMC FAIR Data Dashboard (2.0.0). Zenodo. https://doi.org/10.5281/zenodo.14192862 (opens in a new tab)
Data availability
- A selective export of the dataset included in the dashboard is published on Zenodo (opens in a new tab) and will be updated in regular intervals.